
విషయము

మూలం: Kran77 / Dreamstime.com
Takeaway:
లోతైన అభ్యాస నమూనాలు చాలా ఆహ్లాదకరమైన మరియు ఆసక్తికరమైన ఫలితాలతో కంప్యూటర్లను సొంతంగా ఆలోచించమని బోధిస్తున్నాయి.
లోతైన అభ్యాసం మరింత ఎక్కువ డొమైన్లకు మరియు పరిశ్రమలకు వర్తించబడుతుంది. డ్రైవర్లేని కార్ల నుండి, గో ప్లే చేయడం, చిత్రాల సంగీతాన్ని రూపొందించడం వరకు, ప్రతి రోజు కొత్త లోతైన అభ్యాస నమూనాలు వస్తున్నాయి. ఇక్కడ మేము అనేక ప్రసిద్ధ లోతైన అభ్యాస నమూనాలపైకి వెళ్తాము. శాస్త్రవేత్తలు మరియు డెవలపర్లు ఈ నమూనాలను తీసుకొని వాటిని కొత్త మరియు సృజనాత్మక మార్గాల్లో సవరించుకుంటున్నారు. ఈ ప్రదర్శన మీకు సాధ్యమయ్యేదాన్ని చూడటానికి ప్రేరేపిస్తుందని మేము ఆశిస్తున్నాము. (కృత్రిమ మేధస్సు యొక్క పురోగతి గురించి తెలుసుకోవడానికి, కంప్యూటర్లు మానవ మెదడును అనుకరించగలరా?)
న్యూరల్ స్టైల్
సాఫ్ట్వేర్ నాణ్యత గురించి ఎవరూ పట్టించుకోనప్పుడు మీరు మీ ప్రోగ్రామింగ్ నైపుణ్యాలను మెరుగుపరచలేరు.
న్యూరల్ స్టోరీటెల్లర్

న్యూరల్ స్టోరీటెల్లర్ ఒక మోడల్, ఇది ఒక చిత్రాన్ని ఇచ్చినప్పుడు, చిత్రం గురించి శృంగార కథను సృష్టించగలదు. ఇది ఒక సరదా బొమ్మ మరియు ఇంకా మీరు భవిష్యత్తును imagine హించవచ్చు మరియు ఈ కృత్రిమ మేధస్సు నమూనాలన్నీ కదులుతున్న దిశను చూడవచ్చు.

పై ఫంక్షన్ "స్టైల్-షిఫ్టింగ్" ఆపరేషన్, ఇది మోడల్ను ప్రామాణిక చిత్ర శీర్షికలను నవలల నుండి కథల శైలికి బదిలీ చేయడానికి అనుమతిస్తుంది. స్టైల్ షిఫ్టింగ్ "ఎ న్యూరల్ అల్గోరిథం ఆఫ్ ఆర్టిస్టిక్ స్టైల్" ద్వారా ప్రేరణ పొందింది.
సమాచారం
ఈ నమూనాలో డేటా యొక్క రెండు ప్రధాన వనరులు ఉన్నాయి. MSCOCO అనేది మైక్రోసాఫ్ట్ నుండి 300,000 చిత్రాలను కలిగి ఉన్న డేటాసెట్, ప్రతి చిత్రం ఐదు శీర్షికలను కలిగి ఉంటుంది. MSCOCO మాత్రమే పర్యవేక్షించబడుతున్న డేటా, అంటే మానవులు లోపలికి వెళ్లి ప్రతి చిత్రానికి శీర్షికలను స్పష్టంగా వ్రాయవలసిన డేటా ఇది.
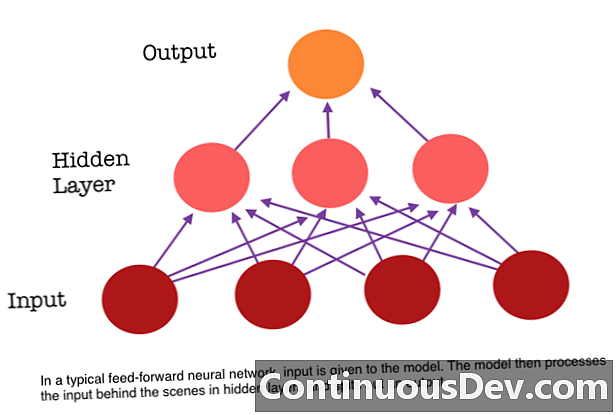
ఫీడ్-ఫార్వర్డ్ న్యూరల్ నెట్వర్క్ యొక్క ప్రధాన పరిమితుల్లో ఒకటి, దానికి జ్ఞాపకశక్తి లేదు. ప్రతి అంచనా మునుపటి లెక్కల నుండి స్వతంత్రంగా ఉంటుంది, ఇది నెట్వర్క్ చేసిన మొట్టమొదటి మరియు ఏకైక అంచనా. కానీ వాక్యం లేదా పేరాను అనువదించడం వంటి అనేక పనుల కోసం, ఇన్పుట్లు వరుస మరియు సంభావిత సంబంధిత డేటాను కలిగి ఉండాలి. ఉదాహరణకు, చుట్టుపక్కల పదాలు అందించిన కాన్ లేకుండా ఒక వాక్యంలో ఒకే పదాన్ని అర్ధం చేసుకోవడం కష్టం.
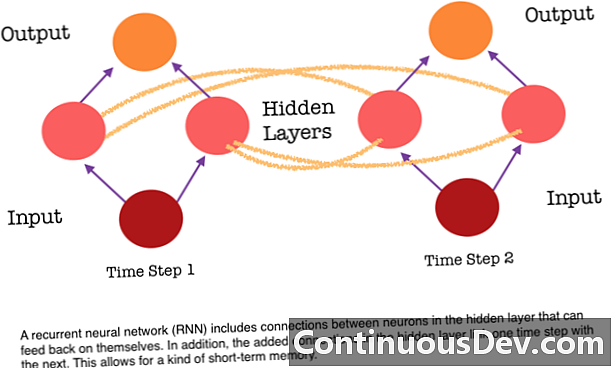
RNN లు భిన్నంగా ఉంటాయి ఎందుకంటే అవి న్యూరాన్ల మధ్య మరొక కనెక్షన్లను జతచేస్తాయి. ఈ లింకులు ఒక దాచిన పొరలోని న్యూరాన్ల నుండి క్రియాశీలతను క్రమం యొక్క తదుపరి దశలో తిరిగి తమలో తాము తిండికి అనుమతిస్తాయి. మరో మాటలో చెప్పాలంటే, అడుగడుగునా, ఒక దాచిన పొర దాని క్రింద ఉన్న పొర నుండి మరియు క్రమం యొక్క మునుపటి దశ నుండి రెండు క్రియాశీలతను పొందుతుంది. ఈ నిర్మాణం తప్పనిసరిగా పునరావృత న్యూరల్ నెట్వర్క్ల మెమరీని ఇస్తుంది. కాబట్టి ఆబ్జెక్ట్ డిటెక్షన్ యొక్క పని కోసం, ప్రస్తుత చిత్రం కుక్క కాదా అని నిర్ణయించడానికి RNN దాని మునుపటి కుక్కల వర్గీకరణలను గీయవచ్చు.
చార్-ఆర్ఎన్ఎన్ టెడ్
దాచిన పొరలోని ఈ సౌకర్యవంతమైన నిర్మాణం అక్షర-స్థాయి భాషా నమూనాలకు RNN లను చాలా బాగుంది. చార్ RNN, మొదట ఆండ్రేజ్ కార్పతి చేత సృష్టించబడినది, ఇది ఒక ఫైల్ను ఇన్పుట్గా తీసుకుంటుంది మరియు తరువాతి అక్షరాన్ని క్రమం లో అంచనా వేయడానికి RNN కి శిక్షణ ఇస్తుంది. RNN అసలు శిక్షణ డేటా వలె కనిపించే అక్షరాల వారీగా పాత్రను సృష్టించగలదు. వివిధ TED చర్చల ట్రాన్స్క్రిప్ట్లను ఉపయోగించి ఒక డెమో శిక్షణ పొందింది. మోడల్ ఒకటి లేదా అనేక కీలకపదాలను ఫీడ్ చేయండి మరియు ఇది TED టాక్ యొక్క వాయిస్ / స్టైల్లో కీవర్డ్ (ల) గురించి ఒక భాగాన్ని సృష్టిస్తుంది.
ముగింపు
ఈ నమూనాలు లోతైన అభ్యాసం కారణంగా సాధ్యమైన యంత్ర మేధస్సులో కొత్త పురోగతులను చూపుతాయి. ఇంతకు ముందెన్నడూ పరిష్కరించలేని సమస్యలను మనం పరిష్కరించగలమని లోతైన అభ్యాసం చూపిస్తుంది మరియు మేము ఇంకా ఆ పీఠభూమికి చేరుకోలేదు. లోతైన అభ్యాస ఆవిష్కరణల ఫలితంగా రాబోయే రెండు సంవత్సరాల్లో డ్రైవర్లెస్ కార్ల వంటి మరెన్నో ఉత్తేజకరమైన విషయాలను చూడాలని ఆశిస్తారు.